
What is a Crawl Budget and How Can You Optimize It?
Google’s shift to a mobile-only Googlebot, the rise of AI Overviews in search results and the escalating battle against “Discovered, not indexed” warnings have demanded crawl budget optimization from technical obscurity into the spotlight. Here’s why:
1. Mobile-Only Googlebot: Crawl Efficiency Just Got Tougher
Google now crawls exclusively using its mobile bot, a seismic shift from its legacy desktop-first approach. This means:
- Sites with clunky mobile experiences (slow load times, unresponsive design) risk having fewer pages crawled.
- Google’s crawl “quota” prioritizes mobile-ready content, leaving desktop-heavy sites in the dust. As one Google engineer noted: “If your site isn’t mobile-friendly, it’s not just users you’ll lose, it’s search engines too.”
2. AI Overviews Demand More (and Better) Data
Google’s AI generated answers, powered by content snippets from crawled pages, require deeper and faster access to high quality information. Sites plagued by crawl waste (broken pages, redirect chains) are often excluded from these AI driven features. In 2025, missing out on AI Overviews isn’t just a ranking issue, it’s a visibility extinction event.
3. “Discovered, Not Indexed” Is the New Normal
Even enterprise sites now grapple with Google’s reluctance to index pages it technically finds. Why?
- Resource constraints: Google’s systems prioritize crawling pages with clear signals of value (internal links, freshness, user engagement).
- Crawl bloat: Sites with duplicate content, orphaned pages or unoptimized JavaScript drain their own crawl budgets.
These trends converge into one truth: crawl budget is no longer a “big site problem.” With mobile-first indexing as the default and AI Overviews dominating SERPs, every site must streamline how Googlebot interacts with its content. In this guide, you’ll learn how to diagnose crawl waste, apply technical and content level fixes and leverage modern tools like IndexPlease to stay ahead. Let’s start with the basics.
1. Crawl Budget 101: Google’s Two Part Formula

Your crawl budget is the number of pages on your website that search engine bots, such as Google, crawl in a certain amount of time. These bots are in control of indexing your website so that it appears in search engine results. Crawl budget isn’t just a single number Google assigns to your site. Instead, it’s a dynamic calculation based on two variables:
- Crawl Rate Limit (How fast Googlebot can crawl your site)
- Crawl Demand (How much Googlebot wants to crawl your site)
Crawl Budget = Crawl Rate Limit × Crawl Demand Let’s break down each component and see why this formula matters more than ever.
Part 1: Crawl Rate Limit - The Technical Speed Bump
Googlebot doesn’t want to overwhelm your server. To prevent this, it calculates a crawl rate limit based on:
- Server health: Response time, uptime and errors.
- Resource constraints: Google’s own infrastructure capacity.
- Historical behavior: If your site crashed during a crawl last week, Googlebot will tread carefully.
Key Factors Impacting Crawl Rate Limit:
- Response Codes: Frequent 404s or 500s signal instability.
- Server Speed: Pages taking >2 seconds to load reduce crawl capacity.
- Core Web Vitals: Largest Contentful Paint (LCP) directly impacts crawl efficiency.
Google’s official guidelines state: “A healthy server can handle more crawls. Fix errors and improve speed to maximize your rate limit.”
Part 2: Crawl Demand – Google’s ‘Interest Level’ in Your Site
Even if your server is lightning fast, Googlebot won’t crawl your site aggressively if it lacks demand signals:
- Internal Links: Pages buried in site architecture are deemed low priority.
- Sitemaps: URLs in XML sitemaps get a crawl priority boost.
- External Signals: Backlinks and mentions on social/media platforms increase urgency.
- Freshness: Frequently updated content (e.g., news, product inventory) gets crawled more often.
Example: A news site publishing 50 articles daily might see only 10 indexed if:
- Articles aren’t linked internally.
- Sitemaps aren’t updated in real time.
- Pages lack backlinks or social shares.
How the Two Parts Work Together
Imagine your site has:
- Crawl Rate Limit: 1,000 pages/day (due to a fast, stable server).
- Crawl Demand: 500 pages (low internal linking, stale sitemap).
Your effective crawl budget = 500 pages/day (1,000 × 0.5 demand ratio). But if you improve internal linking and refresh your sitemap, demand might jump to 0.8. Now, your budget becomes 800 pages/day without touching server settings.
Why This Formula Matters
- Mobile-Only Crawling: Slower mobile render times eat into crawl rate limits.
- AI Overviews: Googlebot now prioritizes crawling pages with “snippet-worthy” content (e.g., FAQs, definitions).
- Resource Competition: With more sites optimizing for crawl efficiency, slower ones get deprioritized.
Key Takeaway
- Fix server issues to maximize crawl rate.
- Boost demand signals to make Googlebot “care” about your pages.
For a deeper dive into discovery mechanics, see our guide: How Search Engines Find New Pages.
2. Diagnosing Your Crawl Budget Health
You can’t fix what you don’t measure. Before optimizing crawl budget, you need to pinpoint where Googlebot is wasting time on your site and why it’s ignoring your most important pages. Here’s how to audit your crawl health using free and paid tools.
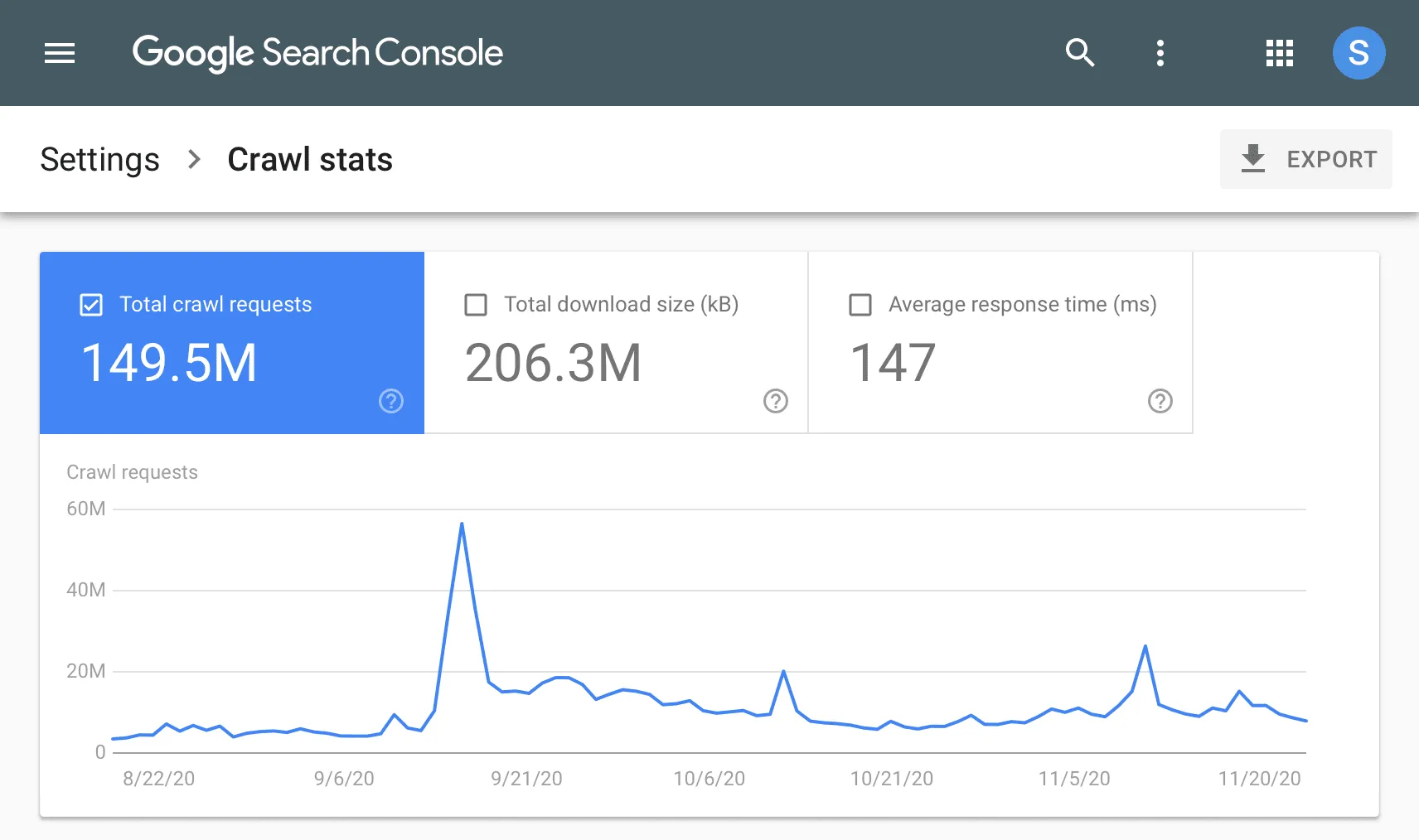
Step 1: Google Search Console (GSC) – The Baseline Checkup
Start with GSC’s Crawl Stats Report (Settings > Crawl Stats). Focus on three metrics:
| Metric | What It Tells You | Ideal Range |
|---|---|---|
| Crawl Requests | Total pages crawled/day | Stable or growing (drastic drops signal penalties or server issues). |
| Data Downloaded | MBs Googlebot consumes | Lower = better. Spikes indicate bloated pages (e.g., unoptimized images). |
| Average Response Time | Server speed | <1.5 seconds. Mobile-first crawling penalizes slower sites. |
Red Flags:
- High 404/500 Errors: >10% of crawl requests.
- Crawl “Peaks and Valleys”: Inconsistent patterns suggest server instability.
Next, check Indexing > Pages for the “Discovered, currently not indexed” count. If this number grows over time, Googlebot is finding pages but choosing not to index them, a sign of low crawl demand.
Step 2: Log File Analysis – The Forensic Deep Dive
Server logs show exactly how Googlebot interacts with your site. Use tools like Screaming Frog Log File Analyzer to:
- Filter for Googlebot Traffic:
- User agent strings: Googlebot Smartphone (mobile), Googlebot Desktop
- Identify Waste:
- Pages returning 404/500 errors.
- Redirect chains (e.g., URL A → B → C).
- Low value URLs (old promotional pages, duplicate filters).
- Track Crawl Frequency:
- Are high priority pages (e.g., new products) crawled daily?
- Are paginated or parameter heavy URLs hogging crawl time?
Step 3: Third Party Tools – Automating the Audit
Semrush Site Audit
- Flags crawlability issues: blocked resources, slow pages, broken links.
- Prioritizes fixes by severity (e.g., “Critical” errors vs. “Warning” 301s).
Ahrefs Site Audit
- Tracks “Crawl Budget Waste” metrics:
- Orphaned pages (no internal links).
- Duplicate content (same H1s, meta titles).
- Redirect chains longer than 3 hops.
Prioritizing Your Findings
Not all issues are equal. Use this hierarchy to triage:
- Critical: Server errors, mobile slowdowns (LCP >4s).
- High: Redirect chains, blocked JS/CSS, orphaned pages.
- Medium: Thin content, minor duplicate pages.
Pro Tip: Compare GSC’s “Crawl Requests” with your log file data. If logs show more crawls than GSC reports, non Google bots (e.g., spam crawlers) may be hogging server resources.
With Googlebot now mobile-only and prioritizing AI ready content, even minor crawl inefficiencies compound:
- A single error on a mobile page can reduce your crawl rate limit by 15–20%.
- Pages not crawled within 24 hours of updates risk exclusion from AI Overviews.
3. Technical Fixes That Free Crawl Budget Fast

Technical crawl waste is like a leaky faucet, draining resources silently but relentlessly. In 2025, with Googlebot’s mobile-only focus and AI Overviews’ hunger for fresh data, fixing these issues isn’t optional. Here’s how to plug the leaks.
1. Eliminate 404s and 5xx Errors: Stop the Bleeding
Every crawl wasted on broken pages is a crawl not spent on your key content.
Why it matters:
- 404s: Googlebot spends ~300ms per error. 1,000 dead URLs = 5 minutes of wasted crawl time daily.
- 5xx Errors: Server crashes trigger Googlebot to throttle your crawl rate limit for days.
How to fix:
- Use Google Search Console (Coverage Report) and Screaming Frog to find broken links.
- Redirect 404s to relevant pages (301) or remove internal links to them.
- For 5xx errors: Monitor server health (tools like UptimeRobot) and optimize database queries.
2. Compress Redirect Chains: Shorten the Detours
Redirects (301/302) are necessary, but chains like URL A → B → C → D slow Googlebot to a crawl.
Why it matters:
- Each redirect adds ~200ms latency. A 3 hop chain = 600ms wasted per crawl.
- Mobile-first crawling amplifies latency due to slower render times.
How to fix:
- Use Ahrefs Site Audit or Semrush to map redirect chains.
- Replace chains with single hops (e.g., A → D directly).
- For parameter heavy URLs (e.g., tracking UTM tags), use rel=canonical instead of redirects.
Pro Tip: Keep redirects under 3 hops. Googlebot may abandon chains longer than 5.
3. Unblock JavaScript/CSS: Let Googlebot “See” Your Pages
Blocking resources via robots.txt prevents Googlebot from rendering pages accurately, leading to indexing errors and recrawls.
Why it matters:
- Googlebot treats mobile pages as users. If JS/CSS is blocked, it can’t assess Core Web Vitals or content.
- Misrendered pages get deprioritized, increasing “Discovered, not indexed” counts.
How to fix:
- Check robots.txt for disallowed .js/.css files.
- Use GSC’s URL Inspection Tool to test rendering.
- For single page apps (SPA), ensure dynamic content loads without requiring user interactions (e.g., clicks).
AI Overviews prioritize pages with structured data and clear content hierarchy, both rely on unblocked resources.
4. Optimize Core Web Vitals: Speed Up Crawl Rate Limits
Google uses Core Web Vitals (CWV) to gauge server health. Poor scores = stricter crawl rate limits.
Key Metrics:
- Largest Contentful Paint (LCP): Aim for <2.5s (mobile).
- Time to First Byte (TTFB): <600ms.
How to fix:
- Implement caching (CDNs like Cloudflare) and compress images (WebP format).
- Upgrade hosting plans for resource heavy sites (e.g., WooCommerce stores).
- Test with PageSpeed Insights and prioritize “Opportunities” flagged in reports.
5. Server Level Optimizations
- Enable HTTP/2: Reduces latency via multiplexed requests.
- Preload Critical Resources: Use
<link rel="preload">for above-the-fold assets. - Lazy Load Images/Video: Defer offscreen media to speed up initial page loads.
With Googlebot’s mobile-only crawling and AI Overviews’ dominance, even minor technical flaws compound:
- A single 5xx error can cost 1,000+ crawls/month on medium sized sites.
- Pages with unblocked JS/CSS are 3x more likely to appear in AI generated answers.
4. Push vs. Pull: How IndexNow & Indexing APIs Shift the Budget Game

Waiting for Googlebot to “discover” your content is a luxury few can afford. Enter push indexing, a paradigm shift where you control when and how search engines access your pages. Here’s how tools like IndexNow and Google’s Indexing API are rewriting the crawl budget playbook.
The Push vs. Pull Crawl Dilemma
- Pull (Traditional): Search engines discover pages via sitemaps, links and organic crawling. Slow, inefficient and budget dependent.
- Push (Modern): You proactively notify search engines about new/updated pages via APIs. Instant, targeted and crawl budget friendly.
Why Push Wins
- AI Overviews prioritize fresh, authoritative content, delays mean missed opportunities.
- Mobile-first crawling’s latency makes traditional discovery unreliable for time sensitive updates.
IndexNow: The Instant Notification Protocol
Developed by Microsoft Bing and adopted by Yandex, IndexNow lets you “ping” search engines the moment content changes.
How It Works:
- Submit a URL (e.g., https://yoursite.com/new-page) to IndexNow’s API.
- Search engines crawl and index the page within minutes, not days.
Benefits:
- Zero Crawl Waste: No waiting for bots to find updates.
- Multi Engine Support: Works with Bing, Yandex and Google (via partnership).
- Easy Setup: Add a simple API key or verify ownership via DNS.
Use Case: A news site used IndexNow to push breaking stories, reducing median indexing time from 12 hours to 8 minutes and freeing 40% of crawl budget for deeper content.
Google’s Indexing API: Precision Control for Critical Pages
Google’s API targets two scenarios:
- Job Postings and Live Streams (officially supported).
- High Value Pages (e.g., product updates, event pages) via creative use.
How It Works:
- Authenticate via Google Cloud’s JSON key.
- Send HTTP POST requests with URLs to notify Google of new/changed content.
Benefits:
- Priority Crawling: Pages submitted via the API jump the crawl queue.
- Real Time Updates: Ideal for pricing changes, limited time offers or event pages.
Limitation: Requires technical setup (OAuth 2.0, JSON credentials) and adherence to Google’s quotas. Combine both. Use IndexNow for general content and Google’s API for mission-critical pages.
How IndexPlease Automates Push Indexing
Tools like IndexPlease bridge the gap between manual submissions and automation:
- Auto Detect Changes: Monitors your CMS for new/updated pages.
- Bulk Submissions: Fires URLs to IndexNow and Google’s API in real-time.
- Quota Management: Avoids overloading APIs with smart scheduling.
Challenges & Best Practices Rate Limits: Google’s API allows ~200 URLs/day per property; IndexNow caps at 10,000/day.
Security: Keep API keys and JSON credentials encrypted. Quality Control: Only push pages with material changes, abusing APIs risks penalties.
Push indexing isn’t just a crawl budget hack, it’s a survival tactic. With AI Overviews scraping content in real time and mobile rendering delays, pages not indexed within hours become irrelevant.
FAQs
1. Do small sites need to care about crawl budget?
Yes. While Googlebot typically crawls small sites aggressively, 2025’s mobile-only crawling and AI Overviews mean inefficiencies hurt faster:
- Slow mobile pages reduce crawl rate limits.
- AI Overviews prioritize fresh, error free content.
Pro Tip: Sites under 500 pages should still fix 404s and server speed.
2. How many redirects are “too many”?
- Single redirects: Safe (e.g., HTTP → HTTPS).
- Chains longer than 3 hops: Harmful. Googlebot may abandon the crawl.
- Worst offenders: Parameter driven redirects (e.g., tracking URLs).
Fix: Audit with Screaming Frog or Ahrefs; consolidate chains.
3. Does crawl delay in robots.txt help?
No. Google ignores the crawl delay directive. Instead:
- Improve server response time.
- Use bot names in robots.txt to block spam crawlers (e.g., User agent: MJ12bot).
4. Can noindex pages drain crawl budget?
Yes. Googlebot still crawls noindex pages if linked internally or in sitemaps. Fix:
- Remove noindex pages from sitemaps.
- Block low priority pages (e.g., filters) via robots.txt and remove internal links.
5. How often should I update my sitemap?
- High velocity sites (news, Ecommerce): Real time updates via API driven sitemaps.
- Static sites: Weekly.
- Twist: AI Overviews prioritize pages in frequently updated sitemaps.
6. Does pagination hurt crawl budget?
It can. Infinite scroll is risky (Googlebot struggles with JS heavy loads). Instead:
- Use rel=next/prev for paginated series.
- Add a “View All” page with canonical tags.
7. Can I “force” Google to crawl my site faster?
Yes, with push tools:
- IndexNow: Free, instant notifications for new pages.
- Google Indexing API: For priority crawling of critical URLs (e.g., restocked products).
- IndexPlease: Automates submissions across APIs to maximize efficiency.
Final Thoughts
Crawl budget optimization is no longer a niche technical task, it’s a survival skill in 2025’s AI driven, mobile-first search landscape. With Googlebot crawling exclusively on mobile and AI Overviews rewarding real time freshness, every wasted crawl erodes your visibility.
Key Takeaways
- Speed is currency: Server health and Core Web Vitals dictate crawl rate limits.
- Relevance drives demand: Structure content for both users and bots (clear hierarchies, internal links).
- Push, don’t pull: Tools like IndexNow and Google’s Indexing API let you bypass crawl bottlenecks entirely.
The sites thriving today treat crawl budget as a finite resource, auditing ruthlessly, fixing relentlessly and automating intelligently.
Ready to Take Control? If manual log analysis or API setups feel overwhelming, IndexPlease simplifies the process:
- Automatically detects new/changed pages.
- Pushes URLs to search engines in real time.
- Monitors crawl health to prevent waste.
Start reclaiming your crawl budget today, try IndexPlease or explore our robots.txt optimization guide to ensure every crawl counts.