
Setting Up a Robots.txt File for Effective Indexing
What is Robots.txt?
The Robots.txt file is a plain text file located at the root of your website (e.g., yourdomain.com/robots.txt) that tells web crawlers (like Googlebot, Bingbot, etc.) what they can and cannot access on your site.
It is a set of ground rules for bots, directing them away from sensitive, irrelevant or duplicate parts of your website while allowing indexing of your valuable content.
Why Is Robots.txt Important?
Controls Crawl Budget: Helps search engines avoid wasting resources crawling unimportant pages.
Improves Indexing Efficiency: Keeps duplicate content, login pages or internal files out of search results.
Boosts SEO: Helps search engines focus on what should rank.
Enhances Security: Blocks access to folders like
/cgi-bin/or/admin/, although it should not be used for real security, just indexing.
Common Directives
User-agent: *
Disallow: /private/
Allow: /public/User-agent: Specifies which crawler the rule applies to (e.g., Googlebot, Bingbot, or*for all).Disallow: Blocks crawlers from accessing a specific folder or URL.Allow: Overrides a previous disallow and explicitly permits access.
What Robots.txt Cannot Do
It doesn’t prevent a page from being indexed if another page links to it.
It is not a security feature, bots can still access and display content if it’s not secured properly.
Doesn’t apply to all bots (some may ignore it).
Good Use Cases
Disallow
/cart/,/checkout/or/login/to avoid thin, private or duplicate content being indexed.Allow only
/blog/and block everything else if you’re running a content-first site.
Point to your sitemap:
Sitemap: https://example.com/sitemap.xml
Pro Tips
Use robots.txt in combination with meta tags (
noindex,nofollow) and canonical tags for full control.Always test your robots.txt using Google Search Console’s “robots.txt tester.”
Don’t block JS/CSS unless absolutely necessary, Google uses them to render pages.
Crawl budgets are tighter, AI scrapers are rampant and a single misconfigured line can still cripple your SEO. This guide isn’t just about avoiding problems, it’s about optimizing indexing in an era where Googlebot’s patience is thinner than ever. By the end, you’ll know how to block the bad, guide the good and keep your traffic flowing.
What is indexing?
Indexing is what happens after a search engine discovers a page on your website, it analyzes the content and decides whether to include it in its search results.
Think of it like a library:
Crawling is the librarian finding a new book (your webpage).
Indexing is the librarian deciding to put that book on the shelf so others can find it later.
Now, here’s where robots.txt comes in.
This tiny file tells search engine bots which pages they’re allowed to crawl. If a page isn’t crawled, it likely won’t be indexed, which means it won’t show up in search results.
Why would you not want something indexed?
It’s a private or test page
It’s a duplicate of another page
It’s not useful to the public
Indexing = getting listed on Google. Robots.txt = the instructions that help search engines decide what to read (or skip).
It’s your first line of control over what shows up in search and what stays behind the curtain.
1. Robots.txt Fundamentals: How Crawlers Read the File
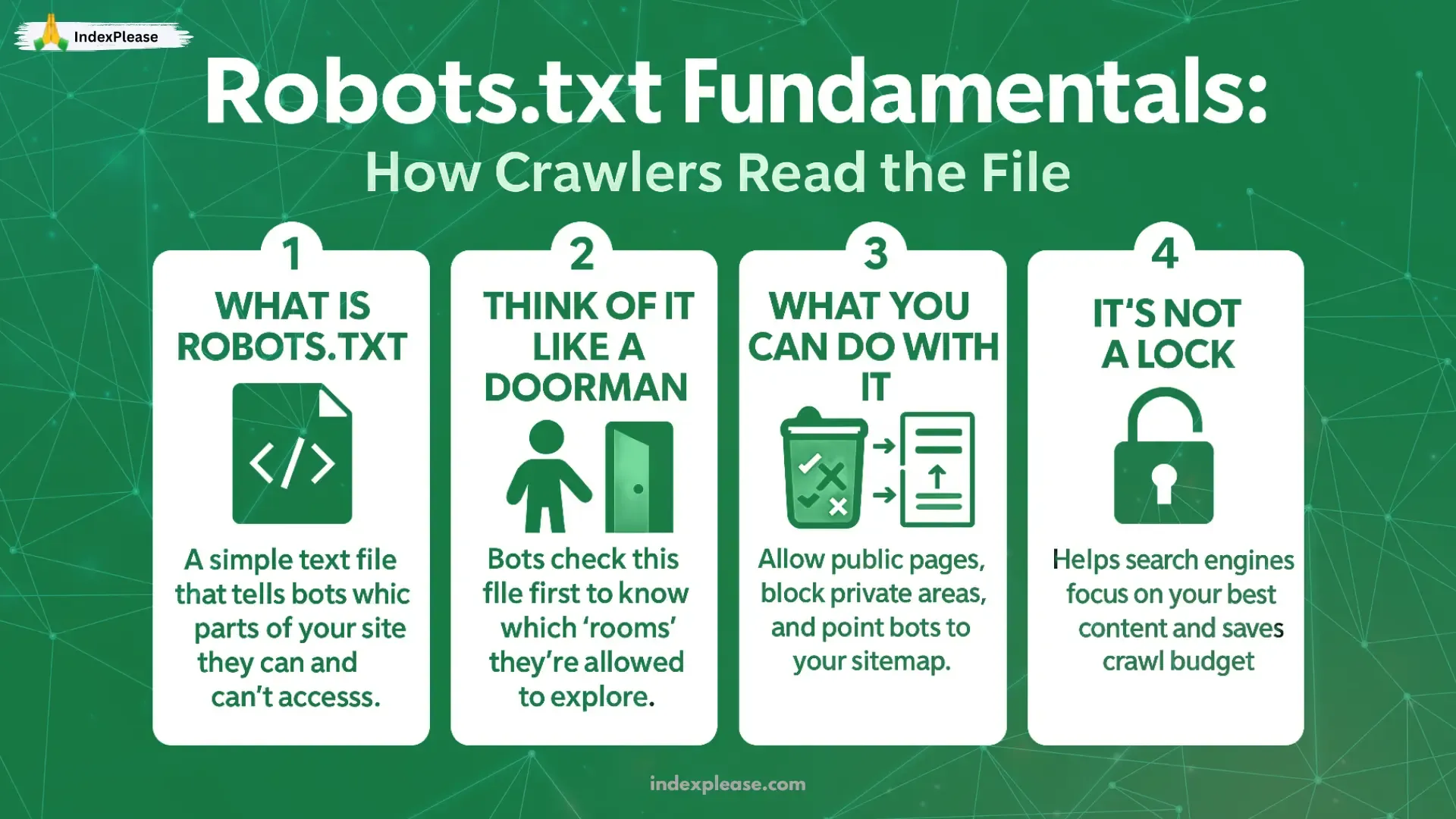
Think of the robots.txt file as a doorman for your website. It’s a short note you leave at the entrance telling search engine bots (like Google) where they’re allowed to go and where they’re not.
When a search engine visits your site, the very first thing it does is check this file. It’s like asking, “Hey, can I come in? And if so, which rooms can I explore?”
You can use robots.txt to:
Allow bots to visit your public pages.
Block them from crawling private or sensitive sections.
Guide them to your sitemap (a full list of pages you do want found).
It doesn’t control what shows up in Google, it just tells bots not to crawl certain areas. Think of it as a “please don’t peek in here” sign, not a locked door.
It’s a simple way to manage your site’s visibility and help search engines spend their time wisely on the content you care about most.
User-Agents
Crawlers like Googlebot follow a strict top down hierarchy. If you write:
User-agent: *
Disallow: /temp/
User-agent: Googlebot
Allow: /temp/urgent-page/Googlebot will still access /temp/urgent-page/ because rules are processed in order. Moz’s 2024 study found that 23% of sites misapply precedence, leading to accidental blocks.
Sitemaps
Use $ to block URL endings (e.g., Disallow: /*.pdf$). While Sitemap: isn’t an official standard, Google and Bing prioritize URLs listed here.
IndexPlease’s “How Search Engines Find New Pages” dives deeper into crawl mechanics.
Common Pitfalls
- Case Sensitivity: Disallow:
/Admin/won’t block/admin/. - Missing Slashes: Disallow: blog allows
/blog/, but Disallow:/blogblocks both.
2. Modern Directives & Myths
The noindex Myth
Google officially deprecated noindex in robots.txt in 2021. Yet, Semrush’s 2024 audit found 14% of sites still use it, wasting crawl budget. Instead, use <meta name="robots" content="noindex" /> or HTTP headers.
Crawl Delay Realities
Google ignores Crawl delay, but Bing respects it. To throttle Bingbot, set Crawl delay: 10 and use Bing Webmaster Tools’ crawl controls.
AI Scrapers & llms.txt
OpenAI’s GPTBot now honors llms.txt, a proposed standard for AI crawlers. Block them with:
User-agent: GPTBot
Disallow: /After updating robots.txt, tools like IndexPlease auto ping search engines to recrawl efficiently.
3**. Crawl Budget Friendly Robots.txt**
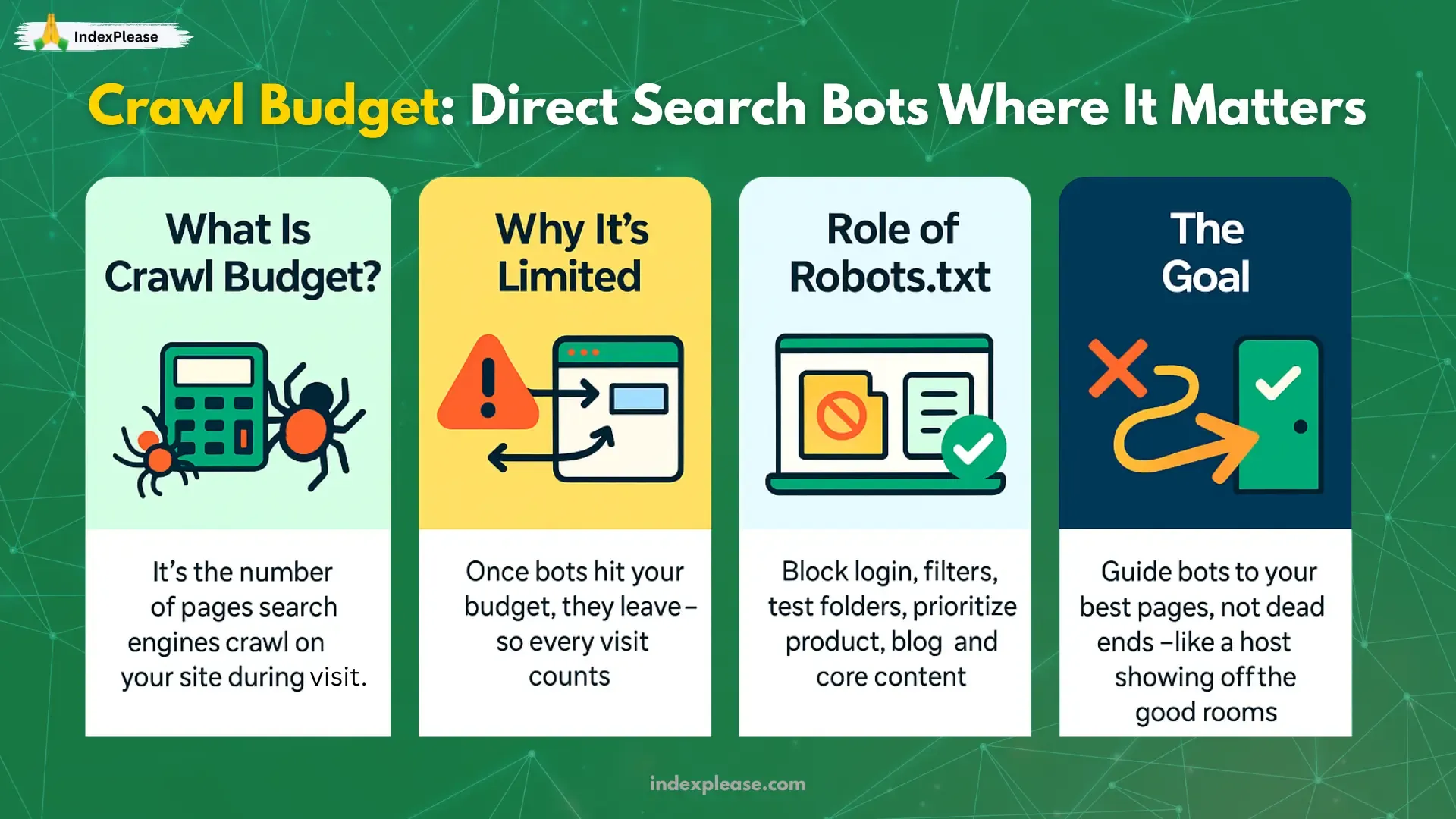
Your website only gets so much “attention” from search engines, that’s called your crawl budget. It’s the number of pages search bots will crawl during a visit. Once they hit that limit, they move on.
So how do you make the most of that limited attention? By building a smart robots.txt file that acts like a traffic director.
With a crawl budget friendly setup, you:
Tell bots to skip the junk like login pages, filters or test folders.
Focus them on what matters for your product pages, blogs and important content.
Avoid wasting crawl time on duplicate or low value pages.
Think of it like guiding a guest through your house: You want them to enjoy the living room, kitchen and garden, not get stuck in the storage closet.
A well structured robots.txt ensures search engines spend their time wisely, helping your best content get discovered faster.
Block Faceted Navigation
Ecommerce sites often leak crawl equity via endless parameters like ?color=red&size=large.
Disallow: /*?color=
Disallow: /*?size=4. Security & Staging
Not all bots are helpful. Some are spam and some can even pose a security risk. That’s where your robots.txt file can act like a security guard.
If you’re running a staging site (a test version of your website) or have private directories you don’t want discovered, robots.txt can politely tell search engines: “Nothing to see here, please move along.”
Here’s what it can help you do:
Block search engines from indexing your developer or staging environments.
Hide sensitive files or internal tools from becoming publicly searchable.
Reduce spam traffic from bad bots by denying access to certain paths.
Note: Robots.txt isn’t a locked door, it’s more like a “do not enter” sign. Good bots (like Google) respect it, but bad ones might not. So pair it with other security measures too. A smart robots.txt can help keep your testing grounds private and protect your site’s integrity, by showing the right bots the way in and the wrong ones the way out.
Password > Robots.txt
A 2024 Ahrefs study showed 8% of companies block sensitive pages (e.g., /admin/) via robots.txt, but those URLs still appear in SERPs as “Uncrawled.” Use authentication instead.
Rate Limit AI Bots
Slow down GPTBot without fully blocking it:
User-agent: GPTBot
Crawl-delay: 20CDN Edge Rules
Cloudflare’s “Bot Fight Mode” blocks malicious bots before they hit your server, complementing robots.txt.
6**. Robots.txt + IndexNow Integration**
Originally, search engines discover your pages slowly, crawling them on their own schedule. But now there’s a faster way to get noticed: IndexNow.
Think of IndexNow as sending a direct message to search engines saying: “Hey, I just published (or updated) something. Come check it out — now.”
And when you combine that with a smart robots.txt file? You’ve got a double win.
Here’s what happens:
Robots.txt helps guide what bots should crawl.
IndexNow tells search engines when something is ready.
Together, they:
Save your crawl budget
Speed up indexing
Give you more control over what’s found and when
If you’re using tools like IndexPlease.com, this integration becomes effortless. You focus on publishing, it handles the rest: pushing updates, guiding crawlers and syncing your robots.txt behind the scenes.
Robots.txt + IndexNow is like having both a map and a megaphone. You show bots where to go and shout when there’s something new.
IndexNow’s push API notifies search engines of changes instantly. Pair it with a clean robots.txt:
- Update robots.txt in your CI/CD pipeline.
- Trigger an IndexPlease webhook to ping Google/Bing.
- New pages index in hours, not weeks.
FAQs
1. What is a robots.txt file and where is it located?
It’s a plain text file placed at the root of your website (e.g., yourdomain.com/robots.txt) that tells search engine crawlers which pages or folders to access or avoid.
2. Why is robots.txt important for SEO?
It helps manage crawl budget, prevents duplicate or sensitive content from being indexed and guides bots to the most valuable content, improving indexing efficiency.
3. Can robots.txt stop a page from being indexed?
No. It only blocks crawling. If another site links to a blocked page, it can still be indexed without being crawled. Use noindex meta tags for true exclusion.
4. What’s the difference between Disallow and Noindex?
Disallow: Tells bots not to crawl a page.Noindex: Tells bots they can crawl but not index the page (must be placed in HTML, not robots.txt since 2021).
5. How do I stop Google from crawling certain sections of my site?
Use the Disallow directive like:
User-agent: Googlebot
Disallow: /private-folder/6. Should I block JavaScript and CSS in robots.txt?
No. Googlebot renders pages like browsers and needs access to JS and CSS files for accurate indexing. Avoid blocking unless absolutely required.
7. Is robots.txt a security feature?
Not at all. It’s only a suggestion to bots. Malicious crawlers can ignore it. For real protection, use authentication and server side security.
8. How does robots.txt affect crawl budget?
By blocking low value or duplicate pages (e.g., filters, test pages), robots.txt lets search engines focus their limited crawl resources on important URLs.
9. Can I use robots.txt with IndexNow?
Yes. While robots.txt guides crawlers, IndexNow instantly notifies them of new or updated content. Combining both ensures smarter, faster indexing.
10. How do I test or debug my robots.txt file?
Use the Google Search Console’s Robots.txt Tester or tools like Screaming Frog. Always validate changes before pushing live to avoid traffic killing mistakes.
Final Thoughts
Your robots.txt isn’t a “set and forget” file, it’s a living map for crawlers. Audit it quarterly, align it with canonicals and integrate push APIs like IndexNow. But even with a perfect setup, indexing delays still happen.
That’s where IndexPlease steps in.
IndexPlease is your SEO automation partner, helping you take control of crawling and indexing. Whether you’re fixing “Discovered - Currently not indexed” issues or launching hundreds of new pages, IndexPlease ensures they’re seen fast.
- Ping new and updated URLs with zero coding
- Integrate with IndexNow, Google APIs and more
- Get real time reports on indexing activity
- Save hours by automating what used to be manual SEO task